When using an LLM to extract data from text or images, you can ask
the chatbot to format it in JSON or any other format that you like. This
works well most of the time, but there’s no guarantee that you’ll get
the exact format you want. In particular, if you’re trying to get JSON,
you’ll find that it’s typically surrounded in ```json, and
you’ll occasionally get text that isn’t valid JSON. To avoid these
problems, you can use a recent LLM feature: structured
data (aka structured output). With structured data, you supply
the type specification that defines the object structure you want and
the LLM ensures that’s what you’ll get back.
Structured data basics
To extract structured data call $chat_structured()
instead of $chat(). You’ll also need to define a type
specification that describes the structure of the data that you want
(more on that shortly). Here’s a simple example that extracts two
specific values from a string:
chat <- chat_openai()
#> Using model = "gpt-4.1".
chat$chat_structured(
"My name is Susan and I'm 13 years old",
type = type_object(
name = type_string(),
age = type_number()
)
)
#> $name
#> [1] "Susan"
#>
#> $age
#> [1] 13The same basic idea works with images too:
chat <- chat_openai()
#> Using model = "gpt-4.1".
chat$chat_structured(
content_image_url("https://www.r-project.org/Rlogo.png"),
type = type_object(
primary_shape = type_string(),
primary_colour = type_string()
)
)
#> $primary_shape
#> [1] "ellipse and letter"
#>
#> $primary_colour
#> [1] "grey and blue"If you need to extract data from multiple prompts, you can use
parallel_chat_structured(). It takes the same arguments as
$chat_structured() with two exceptions: it needs a
chat object since it’s a standalone function, not a method,
and it can take a vector of prompts.
prompts <- list(
"I go by Alex. 42 years on this planet and counting.",
"Pleased to meet you! I'm Jamal, age 27.",
"They call me Li Wei. Nineteen years young.",
"Fatima here. Just celebrated my 35th birthday last week.",
"The name's Robert - 51 years old and proud of it.",
"Kwame here - just hit the big 5-0 this year."
)
type_person <- type_object(
name = type_string(),
age = type_number()
)
chat <- chat_openai()
#> Using model = "gpt-4.1".
parallel_chat_structured(chat, prompts, type = type_person)
#> # A tibble: 6 × 2
#> name age
#> <chr> <dbl>
#> 1 Alex 42
#> 2 Jamal 27
#> 3 Li Wei 19
#> 4 Fatima 35
#> 5 Robert 51
#> 6 Kwame 50(Note that structured data extraction automatically disables tool
calling. You can work around this limitation by doing a regular
$chat() and then using
$chat_structured().)
Data types
To extract structured data effectively, you need to understand how LLMs expect types to be defined, and how those types map to the R types you are familiar with.
Basics
To define your desired type specification (also known as a schema),
you use the type_() functions. These are also used for tool
calling (vignette("tool-calling")), so you might already be
familiar with them.The type functions can be divided into three main
groups:
Scalars represent single values. These are
type_boolean(),type_integer(),type_number(),type_string(), andtype_enum(), which represent a single logical, integer, double, string, and factor value respectively.-
Arrays represent a vector of values of the same type. They are created with
type_array()and require theitemargument which specifies the type of each element. Arrays of scalars are very similar to R’s atomic vectors:type_logical_vector <- type_array(type_boolean()) type_integer_vector <- type_array(type_integer()) type_double_vector <- type_array(type_number()) type_character_vector <- type_array(type_string())You can also have arrays of arrays resemble lists with well defined structures:
list_of_integers <- type_array(type_integer_vector)Arrays of objects (described next) are equivalent to data frames.
-
Objects represent a collection of named values. They are created with
type_object(). Objects can contain any number of scalars, arrays, and other objects. They are similar to named lists in R.type_person2 <- type_object( name = type_string(), age = type_integer(), hobbies = type_array(type_string()) )
Under the hood, these type specifications ensures that the LLM returns correctly structured JSON. But ellmer goes one step further and converts the JSON to the closest R analog. This means:
- Scalars are converted to length-1 vectors.
- Arrays of scalars are converted to vectors.
- Arrays of arrays are converted to unnamed lists.
- Objects are converted to named lists.
- Arrays of objects are converted to data frames.
You can opt-out of this and get plain lists by setting
convert = FALSE.
In addition to defining types, you need to provide the LLM with some
information about what those types represent. This is the purpose of the
first argument, description, a string that describes the
data that you want. This is a good place to ask nicely for other
attributes you’ll like the value to have (e.g. minimum or maximum
values, date formats, …). There’s no guarantee that these requests will
be honoured, but the LLM will try.
type_person3 <- type_object(
"A person",
name = type_string("Name"),
age = type_integer("Age, in years."),
hobbies = type_array(
type_string(),
"List of hobbies. Should be exclusive and brief.",
)
)Missing values
The type functions default to required = TRUE which
means the LLM will try really hard to extract values for you, leading to
hallucinations if the data doesn’t exist. Lets go back to our initial
example extracting names and ages, and give it some inputs that don’t
have names and/or ages.
no_match <- list(
"I like apples",
"What time is it?",
"This cheese is 3 years old",
"My name is Hadley."
)
parallel_chat_structured(chat, no_match, type = type_person)
#> # A tibble: 4 × 2
#> name age
#> <chr> <dbl>
#> 1 apples 0
#> 2 Current Time Request 0
#> 3 cheese 3
#> 4 Hadley 0You can often avoid this problem by setting
required = FALSE:
type_person <- type_object(
name = type_string(required = FALSE),
age = type_number(required = FALSE)
)
parallel_chat_structured(chat, no_match, type = type_person)
#> # A tibble: 4 × 2
#> name age
#> <chr> <dbl>
#> 1 NA NA
#> 2 NA NA
#> 3 cheese 3
#> 4 Hadley NAIn other cases, you may need to adjust your prompt as well. Either way, we strongly recommend that you include both positive and negative examples when testing your structured data extraction code.
Data frames
In most cases, you’ll get a data frame (well, tibble) because you are
using parallel_chat_structured(), where each output row
represents one input prompt. In other cases, you might have a more
complex document where you want a data frame from a single prompt. For
example, imagine that you want to extract some data about people from a
table:
prompt <- r"(
* John Smith. Age: 30. Height: 180 cm. Weight: 80 kg.
* Jane Doe. Age: 25. Height: 5'5". Weight: 110 lb.
* Jose Rodriguez. Age: 40. Height: 190 cm. Weight: 90 kg.
* June Lee | Age: 35 | Height 175 cm | Weight: 70 kg
)"You might be tempted to use a definition similar to R: an object (i.e., a named list) containing multiple arrays (i.e., vectors):
type_people <- type_object(
name = type_array(type_string()),
age = type_array(type_integer()),
height = type_array(type_number("in m")),
weight = type_array(type_number("in kg"))
)
chat <- chat_openai()
#> Using model = "gpt-4.1".
chat$chat_structured(prompt, type = type_people)
#> $name
#> [1] "John Smith" "Jane Doe" "Jose Rodriguez" "June Lee"
#>
#> $age
#> [1] 30 25 40 35
#>
#> $height
#> [1] 1.800 1.651 1.900 1.750
#>
#> $weight
#> [1] 80.0 49.9 90.0 70.0This doesn’t work because there’s no constraint that each array should have the same length, and hence no way for ellmer to know that you really wanted a data frame. Instead, you’ll need to turn the data structure “inside out” and create an array of objects:
type_people <- type_array(
type_object(
name = type_string(),
age = type_integer(),
height = type_number("in m"),
weight = type_number("in kg")
)
)
chat <- chat_openai()
#> Using model = "gpt-4.1".
chat$chat_structured(prompt, type = type_people)
#> # A tibble: 4 × 4
#> name age height weight
#> <chr> <int> <dbl> <dbl>
#> 1 John Smith 30 1.8 80
#> 2 Jane Doe 25 1.65 49.9
#> 3 Jose Rodriguez 40 1.9 90
#> 4 June Lee 35 1.75 70Now ellmer knows what you want and gives you a tibble.
If you’re familiar with the terms row-oriented and column-oriented data frames, this is the same idea. Since most languages don’t possess vectorisation like R, row-oriented data frames are more common.
Note that you’ll generally want to avoid nesting objects inside of
objects as this will generate a data frame where each column is itself a
data frame. You can use tidyr::unpack() to unpack these
df-columns back into a regular flat data frame, but your life will be
simpler if you re-consider the type.
Examples
The following examples, which are closely inspired by the Claude documentation, hint at some of the ways you can use structured data extraction.
Example 1: Article summarisation
text <- readLines(system.file(
"examples/third-party-testing.txt",
package = "ellmer"
))
# url <- "https://www.anthropic.com/news/third-party-testing"
# html <- rvest::read_html(url)
# text <- rvest::html_text2(rvest::html_element(html, "article"))
type_summary <- type_object(
"Summary of the article.",
author = type_string("Name of the article author"),
topics = type_array(
type_string(),
'Array of topics, e.g. ["tech", "politics"]. Should be as specific as possible, and can overlap.'
),
summary = type_string("Summary of the article. One or two paragraphs max"),
coherence = type_integer(
"Coherence of the article's key points, 0-100 (inclusive)"
),
persuasion = type_number("Article's persuasion score, 0.0-1.0 (inclusive)")
)
chat <- chat_openai()
#> Using model = "gpt-4.1".
data <- chat$chat_structured(text, type = type_summary)
cat(data$summary)
#> This article by Anthropic argues that the development and deployment of large-scale generative AI systems, such as their own Claude, require robust third-party testing regimes to ensure safety and build public trust. The authors assert that self-governance and internal testing—while important—are insufficient for the sector as a whole, and draw parallels to product safety standards in industries like food, medicine, and aerospace. They argue for a regime involving effective, broadly-trusted safety tests administered by legitimate third-parties, such as independent companies, academic institutions, and government agencies.
#>
#> Key elements of this vision include requiring only the most powerful and potentially risky models to undergo such tests, coordinating international standards, and focusing resources on national security and other high-stakes domains. The article stresses the need to balance robust safety assurance with not overburdening small companies, avoiding regulatory capture, and maintaining innovation. It discusses the tensions around open-source AI and advocates for a 'minimal viable policy approach' that is both practical and enables feedback. Anthropic highlights ongoing activities to support effective third-party testing and sees this approach as central to advancing societal oversight and preventing both deliberate and accidental harm from AI.
str(data)
#> List of 5
#> $ author : chr "Anthropic Policy Team (implied, no explicit author)"
#> $ topics : chr [1:11] "AI safety" "AI policy" "third-party testing" "regulation" ...
#> $ summary : chr "This article by Anthropic argues that the development and deployment of large-scale generative AI systems, such"| __truncated__
#> $ coherence : int 93
#> $ persuasion: num 0.88Example 2: Named entity recognition
text <- "
John works at Google in New York. He met with Sarah, the CEO of
Acme Inc., last week in San Francisco.
"
type_named_entity <- type_object(
name = type_string("The extracted entity name."),
type = type_enum(c("person", "location", "organization"), "The entity type"),
context = type_string("The context in which the entity appears in the text.")
)
type_named_entities <- type_array(type_named_entity)
chat <- chat_openai()
#> Using model = "gpt-4.1".
chat$chat_structured(text, type = type_named_entities)
#> # A tibble: 6 × 3
#> name type context
#> <chr> <fct> <chr>
#> 1 John person John works at Google in New York.
#> 2 Google organization John works at Google in New York.
#> 3 New York location John works at Google in New York.
#> 4 Sarah person He met with Sarah, the CEO of Acme Inc.
#> 5 Acme Inc. organization Sarah, the CEO of Acme Inc.
#> 6 San Francisco location He met with Sarah... last week in San Fra…Example 3: Sentiment analysis
text <- "
The product was okay, but the customer service was terrible. I probably
won't buy from them again.
"
type_sentiment <- type_object(
"Extract the sentiment scores of a given text. Sentiment scores should sum to 1.",
positive_score = type_number(
"Positive sentiment score, ranging from 0.0 to 1.0."
),
negative_score = type_number(
"Negative sentiment score, ranging from 0.0 to 1.0."
),
neutral_score = type_number(
"Neutral sentiment score, ranging from 0.0 to 1.0."
)
)
chat <- chat_openai()
#> Using model = "gpt-4.1".
str(chat$chat_structured(text, type = type_sentiment))
#> List of 3
#> $ positive_score: num 0.1
#> $ negative_score: num 0.7
#> $ neutral_score : num 0.2Note that while we’ve asked nicely for the scores to sum 1, which they do in this example (at least when I ran the code), this is not guaranteed.
Example 4: Text classification
text <- "The new quantum computing breakthrough could revolutionize the tech industry."
type_score <- type_object(
name = type_enum(
c(
"Politics",
"Sports",
"Technology",
"Entertainment",
"Business",
"Other"
),
"The category name",
),
score = type_number(
"The classification score for the category, ranging from 0.0 to 1.0."
)
)
type_classification <- type_array(
type_score,
description = "Array of classification results. The scores should sum to 1."
)
chat <- chat_openai()
#> Using model = "gpt-4.1".
data <- chat$chat_structured(text, type = type_classification)
data
#> # A tibble: 3 × 2
#> name score
#> <fct> <dbl>
#> 1 Technology 0.95
#> 2 Business 0.04
#> 3 Other 0.01Example 5: Working with unknown keys
type_characteristics <- type_object(
"All characteristics",
.additional_properties = TRUE
)
text <- "
The man is tall, with a beard and a scar on his left cheek. He has a deep voice and wears a black leather jacket.
"
chat <- chat_anthropic("Extract all characteristics of supplied character")
#> Using model = "claude-sonnet-4-5-20250929".
str(chat$chat_structured(text, type = type_characteristics))
#> List of 6
#> $ gender : chr "male"
#> $ height : chr "tall"
#> $ facial_hair : chr "beard"
#> $ distinguishing_marks: chr "scar on left cheek"
#> $ voice : chr "deep voice"
#> $ clothing : chr "black leather jacket"This example only works with Claude, not GPT or Gemini, because only Claude supports adding additional, arbitrary properties.
Example 6: Extracting data from an image
The final example comes from Dan Nguyen (you can see other interesting applications at that link). The goal is to extract structured data from this screenshot:
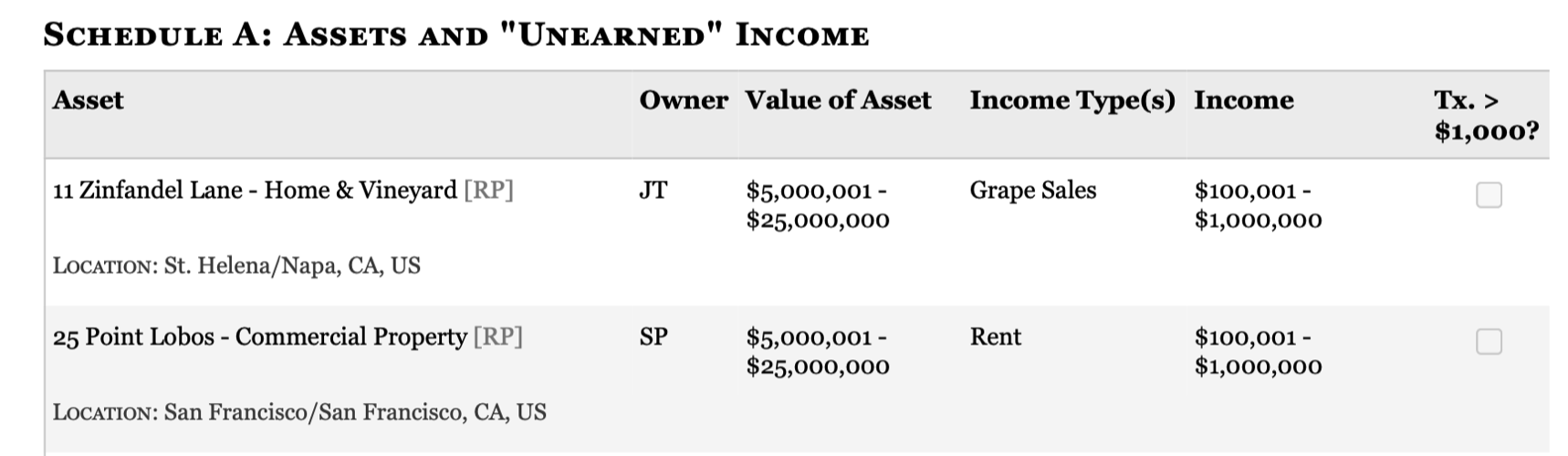
Even without any descriptions, ChatGPT does pretty well:
type_asset <- type_object(
assert_name = type_string(),
owner = type_string(),
location = type_string(),
asset_value_low = type_integer(),
asset_value_high = type_integer(),
income_type = type_string(),
income_low = type_integer(),
income_high = type_integer(),
tx_gt_1000 = type_boolean()
)
type_assets <- type_array(type_asset)
chat <- chat_openai()
image <- content_image_file("congressional-assets.png")
data <- chat$chat_structured(image, type = type_assets)
data